
Paper link | Code link | EMNLP 2023
本研究使用離線強化學習來提高開放式領域對話系統的質量和效用。
在開放式領域對話系統中,維持一致的角色設定至關重要。
與以往依賴於監督學習或在線強化學習的方法不同,本研究使用離線強化學習,這有助於減少訓練過程中重要性權重的變異性。
近年來,大型語言模型在大量未標註的文本數據上進行訓練,並通過額外的微調來處理對話任務。
然而,在社交對話中保持一致性仍然是一個挑戰。以往的方法通過以下途徑來解決這個問題:
BlenderBot3 是一個由 Meta(前身為 Facebook)開發的先進開放式領域對話系統。
它旨在通過結合各種技術,包括大規模預訓練、微調和強化學習,來進行更自然且類人類的對話。
BlenderBot3 以其能夠在廣泛主題中維持一致的角色設定和生成符合上下文的回應而著稱,使其成為對話 AI 領域中更為複雜的模型之一。

他們的離線強化學習訓練方法使用了策略梯度方法來優化強化學習目標。
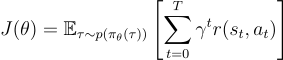
其中,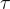 是狀態
是狀態 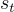 和行為
和行為 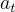 的軌跡,
的軌跡,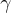 是折扣因子。
是折扣因子。
使用基於策略梯度的離線強化學習方法最大的挑戰是梯度估計器中的高變異性。
在本研究中,他們通過減少策略梯度離線強化學習訓練過程中重要性權重的變異性來解決這個問題。
以下是兩個對話的例子:


本研究使用 DNLI 數據集來評估其方法的有效性。
他們研究中使用的評估指標包括:
以下是比較他們的重要性抽樣技術與 BB3 和 BB3+RL 基線的結果。

以下是他們兩種重要性抽樣技術與 BB3-3B 基線的人工評估結果(範圍從 1 到 5)。


 iThome鐵人賽
iThome鐵人賽